目录
一. Prompt关键要素
二. Prompt技巧
三. 实战中的Prompt优化
四. 参考文献
一. Prompt关键要素
Prompt是一个简短的文本输入,用于引导AI模型生成特定的回答或执行特定任务。换句话说,Prompt是你与AI模型沟通的方式。一个好的Prompt可以让AI更准确地理解你的需求,从而给出更有用的回答。
GPT在处理Prompt时,GPT模型将输入的文本(也就是Prompt)转换为一系列的词向量。然后,模型通过自回归生成过程逐个生成回答中的词汇。在生成每个词时,模型会基于输入的Prompt以及前面生成的所有词来进行预测。这个过程不断重复,直到模型生成完整的回答或达到设定的最大长度。通过这种方式,GPT模型可以根据输入的Prompt来生成回答。这也是为什么一个好的Prompt可以帮助模型更好地理解你的需求,从而提供更有用的回答。
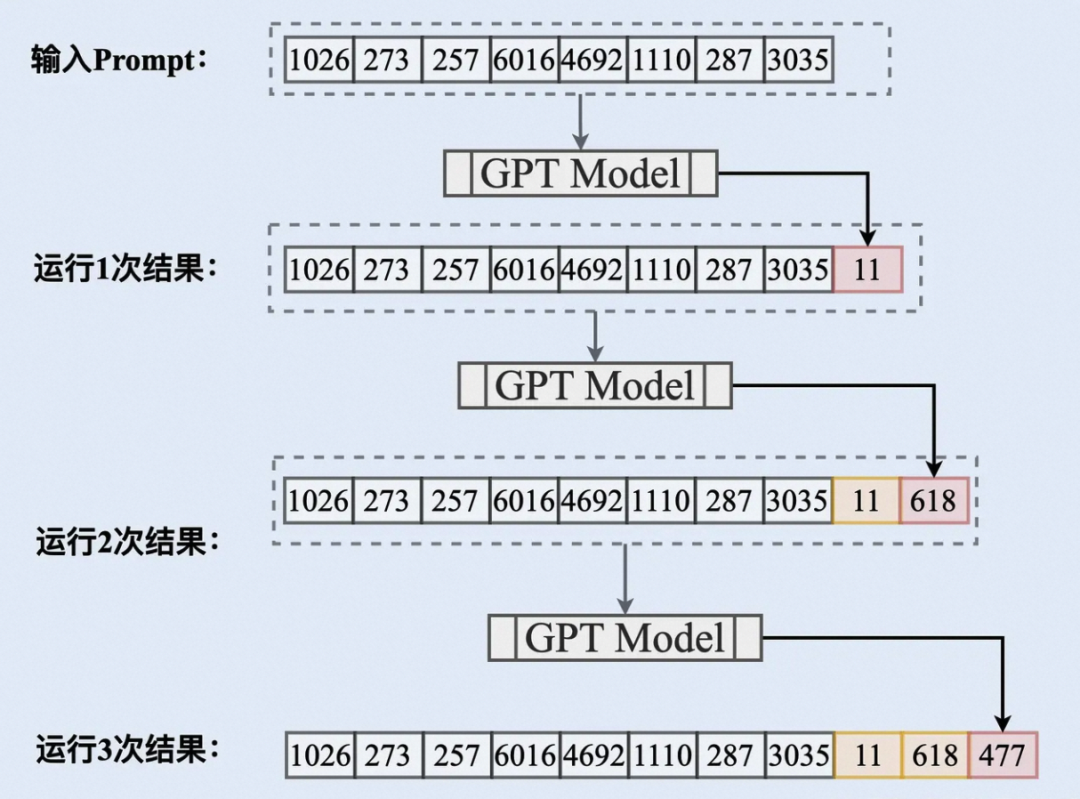
一个完整的Prompt包括以下几个关键要素:
- 明确目标:清晰定义任务,以便模型理解。
- 具体指导:给予模型明确的指导和约束。
- 简洁明了:使用简练、清晰的语言表达Prompt。
- 适当引导:通过示例或问题边界引导模型。
- 迭代优化:根据输出结果,持续调整和优化Prompt。
一些有效做法:
- 强调,可以适当的重复命令和操作。
- 给模型一个出路,如果模型可能无法完成,告诉它说“不知道”,别让它乱“联想”。
- 尽量具体,它还是孩子,少留解读空间。
还有学习提问技巧,例如Socratic questioning(苏格拉底式提问),有助于引导模型更深入地探讨问题,提供更全面的回答。所有得Prompt框架基本上都是这几个部分,不过有些框架更方便记忆,方便我们想起来使用罢了。
Prompt关键要素拆解(重要性降序):
- 任务(Task):始终以动词开始任务句子(如“生成”,“给予”,“写作”等),明确表达你的最终目标。可以有多个。
- 上下文(Context):提供用户背景、成功标准和所处环境等信息。
- 示例(Exemplars):提供具体的例子或框架,以改善输出质量。使用示例或框架可以大大提高输出质量。当然有时候我们可能没有示例,这个时候可以考虑让GPT帮忙生成示例。当然也有很多时候我们不用给示例。
- 角色(Persona):指定你希望ChatGPT和Bard扮演的角色。可以是具体的人,也可以是虚构的角色。
- 格式( Format):可视化你希望输出看起来的样子,表格、列表、段落等。
- 语气(Tone):指定输出的语气。如正式、非正式、豳默等。
二. Prompt技巧
1. 吴恩达Prompt原则
- 原则1:尽可能保证下达的指令“清晰、没有歧义”
- 原则2:给大模型思考的时间,以及足够的时间去完成任务
2. CoT链式思考
思维链(CoT)提示过程鼓励大语言模型解释其推理过程。
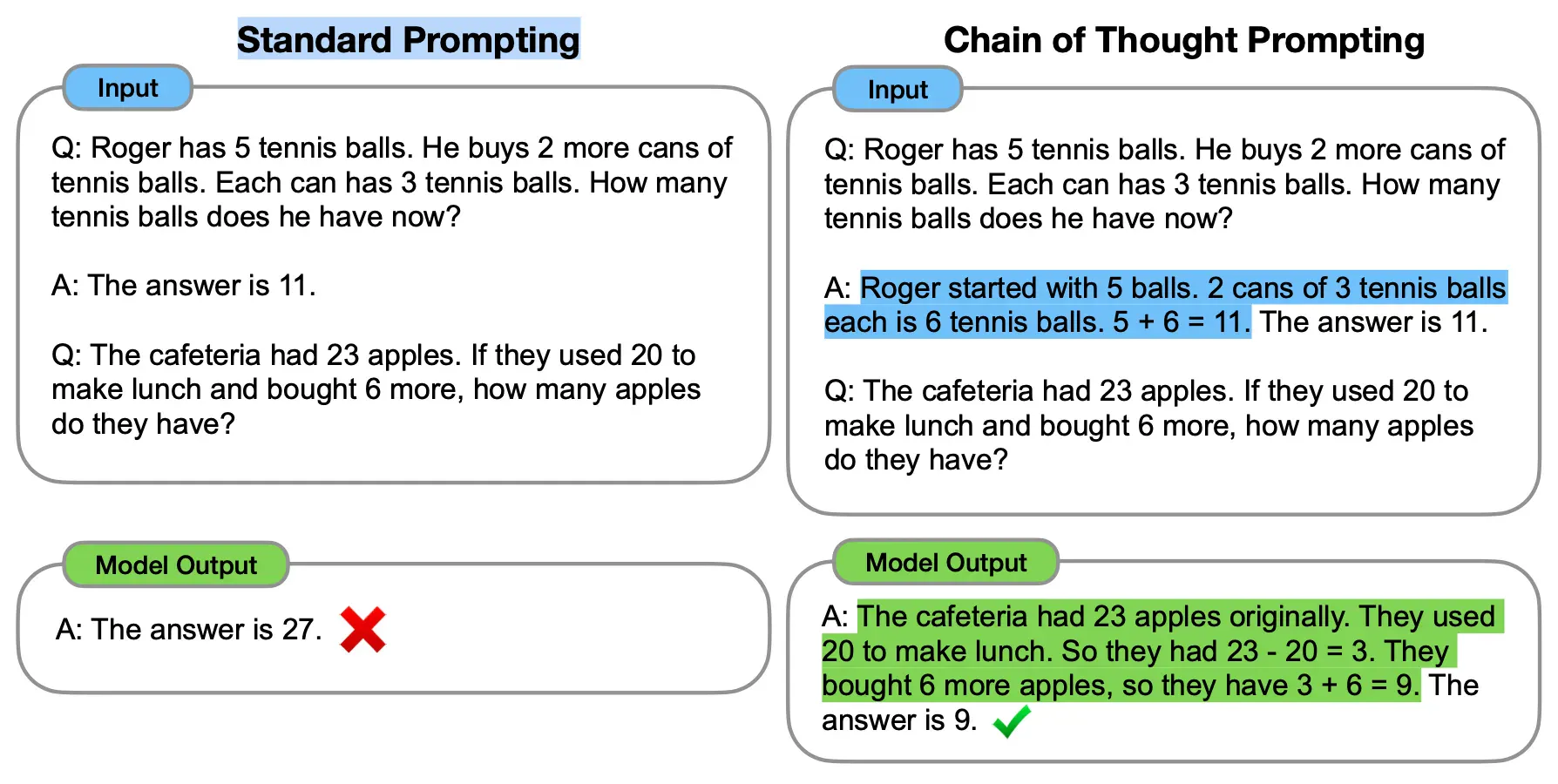
重要的是,根据Wei等人的说法,“思维链仅在使用∼100B参数的模型时才会产生性能提升”。较小的模型编写了不合逻辑的思维链会导致精度比标准提示更差。通常,模型从思维链提示过程中获得性能提升的方式与模型的大小成比例。
参考文档:
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models.
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems.
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., … Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathway
3. 零样本思维链
零样本思维链(Zero Shot Chain of Thought,Zero-shot-CoT)提示过程是对CoT prompting的后续研究,引入了一种非常简单的零样本提示。他们发现,通过在问题的结尾附加“让我们一步步思考。”这几个词,大语言模型能够生成一个回答问题的思维链。从这个思维链中,他们能够提取更准确的答案。

从技术上讲,完整的零样本思维链过程涉及两个单独的提示/补全结果。在下面的图像中,左侧的顶部气泡生成一个思维链,而右侧的顶部气泡接收来自第一个提示(包括第一个提示本身)的输出,并从思维链中提取答案。这个第二个提示是一个自我增强的提示。
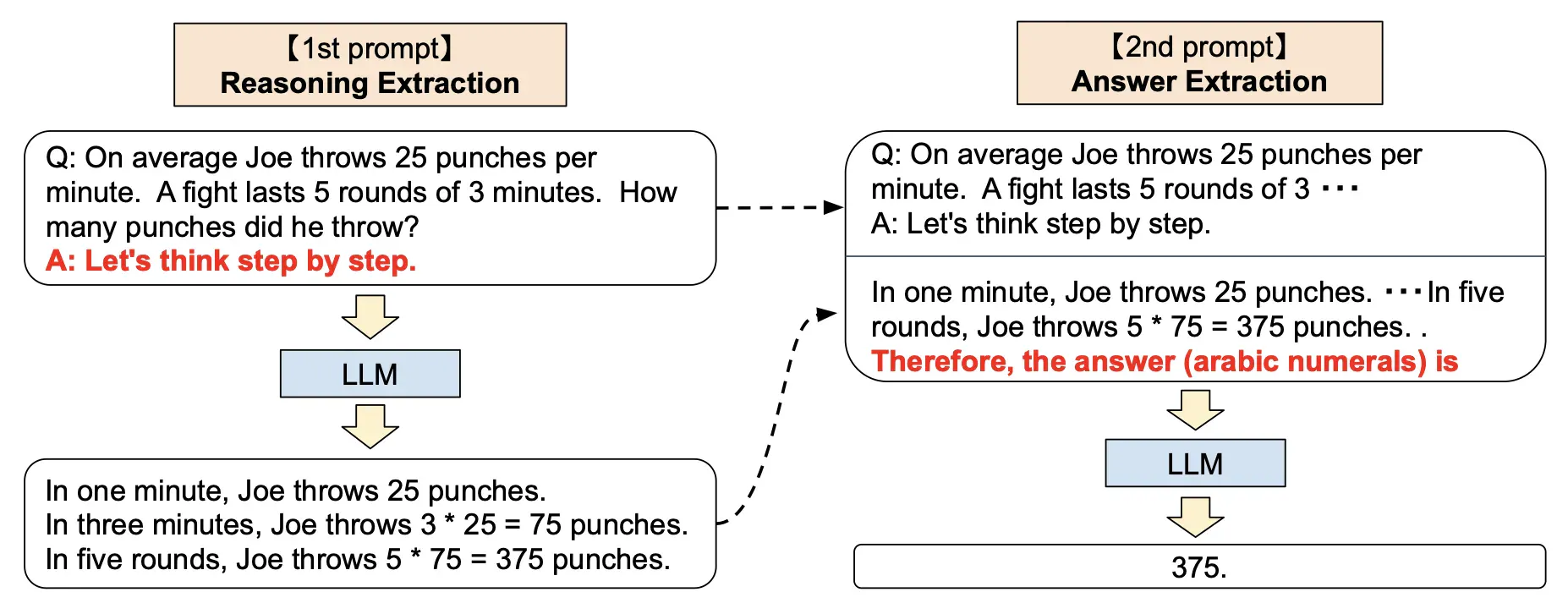
零样本思维链也有效地改善了算术、常识和符号推理任务的结果。然而,它通常不如思维链提示过程有效。在获取思维链提示的少量示例有困难的时候,零样本思维链可以派上用场。
Kojima等人尝试了许多不同的零样本思维链提示(例如“让我们按步骤解决这个问题。”或“让我们逻辑思考一下。”),但他们发现“让我们一步一步地思考”对于他们选择的任务最有效。
参考文档:
- Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2022). Large Language Models are Zero-Shot Reasoners.
4. 自洽性
自洽性(Self-consistency)是对CoT prompting的一个补充,它不仅仅生成一个思路链,而是生成多个思路链,然后取多数答案作为最终答案。
在下面的图中,左侧的提示是使用少样本思路链范例编写的。使用这个提示,独立生成多个思路链,从每个思路链中提取答案,通过“边缘化推理路径”来计算最终答案。实际上,这意味着取多数答案。
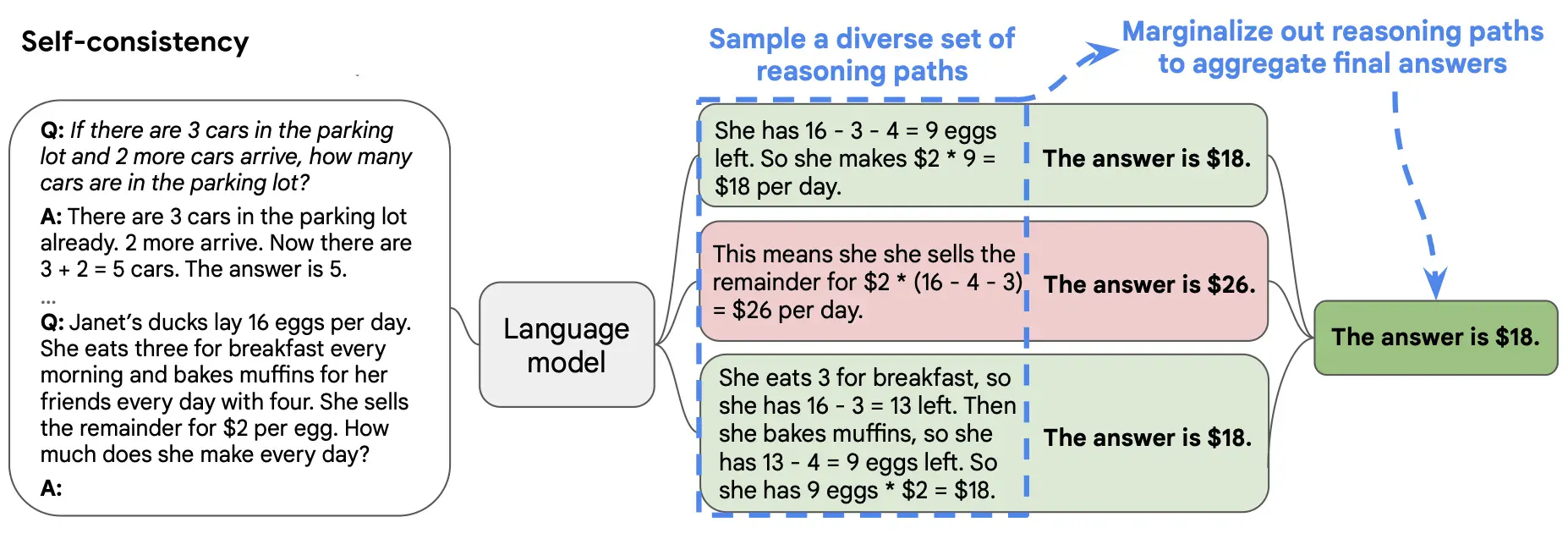
研究表明,自洽性可以提高算术、常识和符号推理任务的结果。即使普通的思路链提示被发现无效,自洽性仍然能够改善结果。
参考文档:
- Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., & Zhou, D. (2022). Self-Consistency Improves Chain of Thought Reasoning in Language Models.
- Ye, X., & Durrett, G. (2022). The Unreliability of Explanations in Few-shot Prompting for Textual Reasoning.
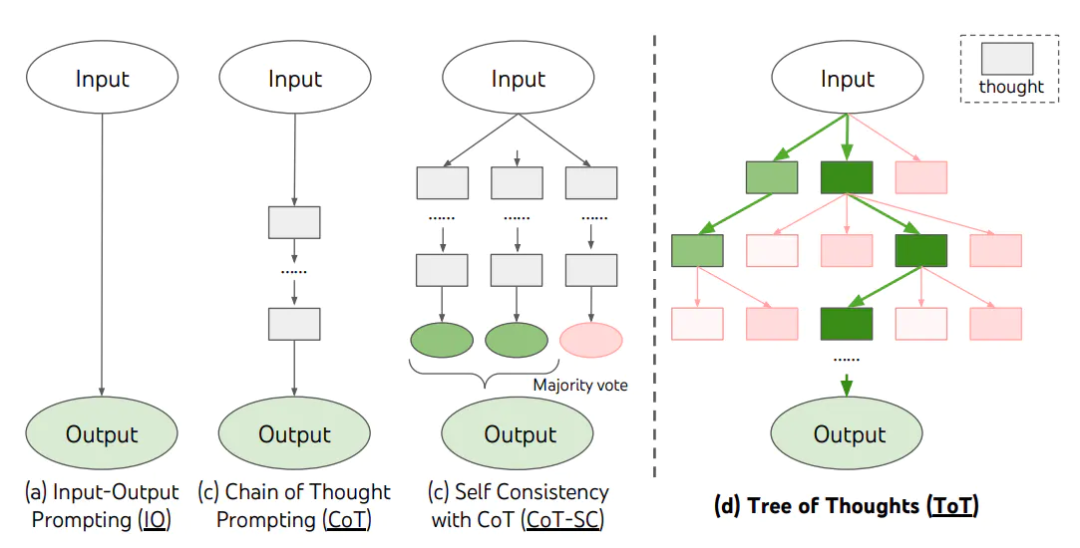
5. 思维树
思维树(Tree of Thoughts,ToT)维护着一棵思维树,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。使用这种方法,LM 能够自己对严谨推理过程的中间思维进行评估。
现有的大模型解决问题的缺陷主要有两个:
- 在局部,没有探索思维过程中的不同延续--类似于树的分支。
- 在全局范围内,没有纳入任何类型的规划、前瞻或回溯,以帮助评估这些不同的选择--而启发式指导的搜索是人类解决问题的特征。
思维树ToT则允许模型探索多种思想推理路径,把所有问题都看作是在一棵树上的搜索,树上的每个节点都代表着一个状态(输入的部分解决方案和截至目前为止的思想序列)。
ToT包含四个过程:
- 问题分解(Thought decomposition):ToT的第一步首先在于将复杂问题拆解成为小问题。由于ToT方法要求模型在每一节点产生多种方案,因此对于问题拆解的要求较高,拆解后的问题不宜过大也不宜过小。
- 思维生成器(Thought generator):1. 取样:从CoT提示中产生i.i.d.的思维,适用于思维是一段话时(思维空间丰富) 2. 提议:当思想空间比较受限时(例如每个思想只是一个词或一行字),这种方法效果更好,使用一个propose prompt依次提出思维;
- 如何启发式地评估状态:1.估值(eg. 评估该状态为sure/likely/impossible) 2.投票;
- 使用何种搜索算法(BFS,DFS,A*,MCTS等)。
官方给的一个触发ToT的方式是:
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...参考文档:
- Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., & Narasimhan, K. (2024). Tree of thoughts: Deliberate problem solving with large language models.Advances in Neural Information Processing Systems,36.
- Tree of Thoughts(ToT)让大模型能动地解决问题
- [Paper Reading] 思维树 Tree of Thoughts
- Prompt提示工程上手指南:基础原理及实践-思维树 (ToT)策略下的Prompt
6. 其他技巧
- 与其告知模型不能干什么,不妨告诉模型能干什么。
- 增加示例:有时候很难描述让模型做的事情,这个时候给出示例就会更好。
- 通过格式阐述要输出的格式。
三. 实战中的Prompt优化
任务描述:希望大模型从大量OCR文本信息中提取与商品描述相关的信息,输出json格式。
目标Prompt:{goods}代表商品类别
用户问题:给你一段输入文本,请从里面提炼与{goods}相关的以下信息:
品牌:商品的品牌
品类:商品的品类
属性:商品除品牌、品类外能够提炼的其他属性,以json形式给出
商品名称:根据提取的信息输出商品描述1. 数据隐私与安全性问题
问题描述:当Promt中出现以1开头的11位电话号码或18位身份证号时,调用GPT时会报错。
解决方法:采用正则化方法,替换其中的电话号码或身份证号。
import re
# 假设这是你要处理的字符串
text = "这里是一些文本 13929398152 这里可能还包含其他数字44150619930103121x结束。"
# 创建一个正则表达式模式
#电话号码 以1开头的11位数字
pattern1 = r"(?<!\d)1\d{10}(?!\d)"
#身份证号 18位数字或17位数字+X/x
pattern2 = r"(?<!\d)\d{18}(?!\d)|(?<!\d)[0-9]{17}[Xx](?!\d)"
# 使用sub方法替换所有匹配的电话号码为空字符串(即删除它们)
cleaned_text = re.sub(pattern1, "", text)
cleaned_text = re.sub(pattern2, "", cleaned_text)
# 打印处理后的字符串
print(cleaned_text)
#输出:这里是一些文本这里可能还包含其他数字结束。2. 使用分隔符清楚地区分输入的不同内容
用分隔符清楚地区分不同部分的内容,可以让模型更好地理解提示所想表达的含义,分隔符可以是''',""",<>,<tag></tag>等。
<context>
{ocr_result}
</context>
根据<context>里的信息回答用户问题3. 结构化输出
有时候我们希望大模型可以输出JSON结构的数据。以往可以利用提示词将输出内容输出位JSON,但是实际上还是字符串。在Langchain中直接封装了这项功能,通过Prompt的输出解析器,可以直接将LLM的输出结果转为指定格式。
#定义输出格式
response_schemas = [
ResponseSchema(name="品牌", description="商品的品牌"),
ResponseSchema(name="品类", description="商品的品类"),
ResponseSchema(name="属性", description="商品除品牌、品类外能够提炼的其他属性"),
ResponseSchema(name="商品名称", description="根据提取的信息输出商品名称"),
]
# 初始化解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()然后只需要将生成的instructions加入到Prompt中即可:
输出格式: {format_instructions}在实际应用中发现,尽管定义了输出格式,但是输出的JSON偶尔会存在不合法的情况,因此需要加入以下提示来保证JSON合法:Json合法性判断工具
保证输出json的合法性4. 给模型一条"出路"
这是为了让模型在没有满足条件时不乱输出,因为按照补全的逻辑,无论你输入什么GPT都会给你补全。
只提取和{goods}相关的信息,如果无法提炼返回空json.5. 让模型"一步步思考"并强制输出思考过程
研究表明,在Prompt中输入"让我们一步步思考"时,大模型能够推理出更准确的结果。但是由于全面制定了输出格式,因此大模型有很大可能不会将思考的过程输出,从而导致我们没有办法根据大模型思考的过程优化Prompt,因此我们强制输出其思考过程:
让我们一步一步分析,给出你分析的过程.优化效果:
ocr = '近三个月订单-未付款-暂停-待出库-待发货-工发-商品信息-单价/数量-货款金额-订单号-下单时间-2024-01-0821-03付款时间-2024-01-0821-03完-安吉尔智能茶吧机CB3482-¥1998-00-在线支付-双屏显示远程遥控多档调-x1-¥1099-00-温24小时恒温家用办公全-优惠明细-当前页货款金额-X'
#优化前:
```json
{
"品牌": "安吉尔",
"品类": "智能茶吧机",
"属性": {
"型号": "CB3482",
"价格": "1998",
"特点": ["双屏显示", "远程遥控", "多档调温", "24小时恒温", "适用场景": "家用办公"]
},
"商品名称": "安吉尔智能茶吧机CB3482"
}
```
#优化后:
分析过程:
1. **品牌识别**:文本中提到了“安吉尔智能茶吧机CB3482”,其中“安吉尔”是一个知名的饮水机品牌,因此可以确定品牌为“安吉尔”。
2. **品类确定**:根据描述“智能茶吧机”,可以推断出商品的品类是“智能茶吧机”,这是一种特定类型的饮水机,专门设计用于制作和分配茶。
3. **属性提取**:从文本中可以提取出以下属性:
- 型号:CB3482
- 价格:¥1998
- 特性:双屏显示、远程遥控、多档调温、24小时恒温
- 适用场合:家用、办公
这些信息可以帮助我们更好地了解产品的特点和适用环境。
4. **商品名称构建**:根据提取的信息,商品名称可以构建为“安吉尔智能茶吧机CB3482 双屏显示远程遥控多档调温24小时恒温家用办公”。
综上所述,我们可以得出以下JSON输出:
```json
{
"品牌": "安吉尔",
"品类": "智能茶吧机",
"属性": {
"型号": "CB3482",
"价格": "¥1998",
"特性": ["双屏显示", "远程遥控", "多档调温", "24小时恒温"],
"适用场合": ["家用", "办公"]
},
"商品名称": "安吉尔智能茶吧机CB3482 双屏显示远程遥控多档调温24小时恒温家用办公"
}
```
这个过程中,我们注意到了品牌和品类的识别,同时也提取了商品的关键属性,这些信息共同构成了一个完整的商品描述。完整Prompt:
HumanPrompt = PromptTemplate(
template="""
用户问题:给你一段输入文本,请从里面提炼与{goods}相关的以下信息:
品牌:商品的品牌
品类:商品的品类
属性:商品除品牌、品类外能够提炼的其他属性,以json形式给出
商品名称:根据提取的信息输出商品描述
<context>
{ocr_result}
</context>
根据<context>里的信息回答用户问题
输出格式: {format_instructions}
让我们一步一步分析,给出你分析的过程,并注意以下要点:
1.只提取和{goods}相关的信息,如果无法提炼返回空json.由于是OCR识别的文本,可能有错误识别,允许对商品信息适当修复.只输出一个可能性最大的商品信息,输出的json只包含一种商品;
2:参考{industry}行业内的常见品牌,并将文本中识别错误的品牌信息,根据字体之间的相似性与已有品牌进行对应;
3.一般来说商品的品牌会在商品描述的前面,并且他们距离不会太远,如果提取到多个品牌信息,则考虑品牌和商品描述之间的距离;
4.你需要判断提取到的品牌是否属于{industry}行业,因为OCR识别的文本中可能有水印信息,若提取到的品牌明显不属于{industry}行业,则忽略该品牌信息;
5.保证输出json的合法性,输出你分析的过程.
""",
input_variables=["goods","ocr_result","format_instructions","industry"]
)四. 参考文献
GPT Prompt编写的艺术:如何提高AI模型的表现力
编写Prompt的艺术:如何提高大语言模型的表现力(附下载方式)
Learning Prompt
大语言模型Prompt工程-原理详解篇
Prompt中文指南(一)基本结构与编写原则
Prompt学习网站:
| https://learningprompt.wiki/ | 免费的 Prompt Engineering 教程,现已包含 ChatGPT 和 Midjourney 教程 |
| https://flowgpt.com/ | 寻找并使用最好的Prompt。 |
| https://www.aishort.top/ | 让生产力加倍的 ChatGPT 快捷指令 |
| https://www.clickprompt.org/zh-CN/ | 支持多种基于 Prompt 的 AI 应用 |



![[柏鹭杯 2021]试试大数据分解?](https://img-blog.csdnimg.cn/direct/f2684e35f6854d7e8ca5fe2ca763b9a1.png)